The Security Gaps in OpenClaw's Skill Ecosystem and Why Cryptographic Proof Might Be the Fix
OpenClaw is the fastest-growing open-source project in history. In under three months it exploded to 193K+ GitHub stars and 416K npm downloads per month, becoming the default open protocol for AI agents to interact across messaging channels. Creator Peter Steinberger joining OpenAI in February 2026, with the project moving to an open-source foundation, only accelerated adoption.
But OpenClaw has a security problem. Not a theoretical one but a well-documented, actively exploited one. And the current approach to fixing it is fundamentally inadequate.
This post explains the three categories of security vulnerabilities in OpenClaw's skill ecosystem, why existing mitigations (including the VirusTotal partnership) fall short, and how cryptographic verification, the approach we've built at Prufold Labs with ClawCheck, provides mathematical guarantees where probabilistic detection cannot.
The Three Vulnerability Classes
1. Third-Party Skill Data Exfiltration
Cisco's AI security team discovered that third-party OpenClaw skills can exfiltrate user data through seemingly benign API calls. Their Skill Scanner identified a malicious skill called "What Would Elon Do?" that ranked #1 in the skill repository while actively exfiltrating data via curl commands to external servers. A skill that claims to "summarize your emails" can silently forward conversation context, and this could include PII, credentials, and proprietary business data, to external endpoints.
This is not an isolated incident. In the ClawHavoc supply-chain attack, threat actors compromised OpenClaw's ClawHub marketplace by mass-uploading 1,184 malicious skills that hid weaponized instructions in README files to trick users into executing malware, reverse shells, and data exfiltration (including AMOS macOS Stealer). The attack surface is enormous: OpenClaw supports 13+ messaging channels (WhatsApp, Telegram, Slack, Discord, Signal, and more), meaning a single malicious skill can harvest data from every channel simultaneously.
The core issue: OpenClaw's skill execution model trusts skills by default. There is no mechanism to verify what a skill actually does at runtime versus what it claims to do.
2. Authentication Bypass (CVE-2026-25253)
CVE-2026-25253 exposed a WebSocket authentication bypass in OpenClaw's transport layer. An attacker could connect to an OpenClaw server without valid credentials, enabling unauthorized access to any connected AI agent and its conversation history.
WebSocket authentication is a known hard problem, but in the context of AI agents handling sensitive data (financial transactions, legal consultations, medical information) an auth bypass is not just a security bug. It's a compliance catastrophe.
The patch addressed the immediate vulnerability, but the deeper architectural issue remains: there is no cryptographic attestation of connection authenticity. A patched server looks identical to a compromised one from the client's perspective.
3. Crypto Scam Social Engineering
During OpenClaw's rapid growth and rebranding phases, crypto scammers targeted users with fake skills and phishing campaigns. This is the inevitable consequence of explosive open-source adoption without a cryptographic trust chain: when anyone can publish a skill, users have no way to verify provenance.
The VirusTotal partnership for skill scanning was a step in the right direction, but it addresses symptoms, not the root cause. VirusTotal scans for known malware signatures, a probabilistic, pattern-matching approach that misses novel attacks and provides no guarantee about what a skill will do in production.
Why Probabilistic Detection Isn't Enough
Every AI security tool on the market today, including the ones recently acquired for hundreds of millions (Protect AI for $700M, Robust Intelligence for $400M, Lakera for $300M, Prompt Security for $250M), uses the same fundamental approach: ML-based classifiers that detect suspicious patterns.
This approach has three irreducible limitations:
False negatives are guaranteed. ML classifiers learn from training data. A novel exfiltration technique that doesn't match known patterns will pass undetected. In security, one false negative can be catastrophic.
No proof of correctness. A probabilistic scanner can say "we didn't find anything suspicious" but cannot say "we guarantee this skill does exactly what it claims and nothing else." The difference matters enormously when regulators start demanding provable compliance, which they will, starting August 2, 2026, when EU AI Act high-risk system requirements take effect.
Runtime behavior diverges from static analysis. A skill can pass every static scan and still behave maliciously at runtime. Context-dependent attacks, time-delayed exfiltration, and polymorphic code all defeat scan-time detection.
The Cryptographic Alternative: What ClawCheck Does Differently
ClawCheck takes a fundamentally different approach. Instead of trying to detect bad behavior (probabilistic), it proves good behavior (deterministic). The system provides six cryptographic guarantees for AI gateway security:
Model Identity Verification
Every AI model invocation is cryptographically attested. When an OpenClaw skill calls GPT-4, Claude, or any other model, ClawCheck generates a proof that the specific model version was actually used - not a cheaper substitute, not a fine-tuned variant, not a malicious wrapper. This uses TEE (Trusted Execution Environment) attestation: the hardware itself certifies what code ran.
Audit Integrity
Every interaction - every message, every skill invocation, every API call - is recorded in a SCITT-aligned (Supply Chain Integrity, Transparency, and Trust) transparency log. These logs are append-only and tamper-evident: any modification is cryptographically detectable. This isn't "logging" in the traditional sense. It's a mathematical guarantee that the audit trail is complete and unaltered.
Tamper Resistance
ZK (zero-knowledge) proofs verify that inputs, outputs, and intermediate computations have not been modified. If a skill claims to have processed your data in a specific way, ClawCheck can prove it, without revealing the data itself. We use SP1 as our ZK prover, which provides fast proof generation suitable for real-time AI gateway traffic.
Policy Enforcement
Security policies (data handling rules, access controls, retention limits) are enforced cryptographically, not just checked procedurally. A policy violation is not just flagged. It is made mathematically impossible.
Non-Repudiation
No party (not the user, not the skill developer, not the platform operator) can deny their actions. Every action is cryptographically signed and attributable.
Transparency
All verification proofs are publicly auditable via the transparency log. Trust doesn't require trusting any single party; it only requires trusting the mathematics.
How It Works with OpenClaw
ClawCheck integrates as an OpenClaw security skill. It runs alongside your other skills and wraps the entire interaction pipeline with cryptographic guarantees. Here's what happens when a user sends a message:
User Message → OpenClaw Router
↓
ClawCheck Intercept (Node.js → NAPI bridge → Rust core)
├── Verify channel authentication (JWT + gateway token)
├── Check skill provenance (cryptographic signature verification)
├── PII detection + AES-256-GCM per-channel encryption
└── Generate transparency log entry (→ VCTS on :8080)
↓
Skill Execution (isolated container, non-root, capabilities dropped)
↓
ClawCheck Output Verification (Rust core → SP1 prover)
├── ZK proof of computation integrity
├── Output policy compliance check (Lean-verified properties)
└── Append to SCITT transparency log (VCTS)
↓
User Response (with verifiable proof chain)What This Means for Compliance
The regulatory landscape is moving from "detect problems" to "prove compliance." EU AI Act Article 12 requires automatic logging of AI system operations. Article 15 requires accuracy, robustness, and cybersecurity with technical measures. Article 19 requires automatically generated logs for high-risk systems. California SB 53, already in effect since January 1, 2026, requires frontier AI developers to publish safety frameworks with $1M fines per violation. A 42-state AG coalition is coordinating AI enforcement.
ClawCheck's six guarantees map directly to these requirements. Model identity verification addresses Article 11 (Technical Documentation). Audit integrity maps to Articles 12 and 19 (Record-Keeping). Tamper resistance fulfills Article 15. Policy enforcement satisfies Article 9 (Risk Management). No probabilistic scanner can provide this mapping. You cannot prove compliance with a "we didn't find anything suspicious" report. You need mathematical proof.
Try It
If you're running OpenClaw in production, or planning to, you probably have a security checklist that's growing faster than your team can address it. We built ClawCheck because we kept seeing the same pattern: organizations adopting AI agents at speed, then scrambling to retrofit security afterward.
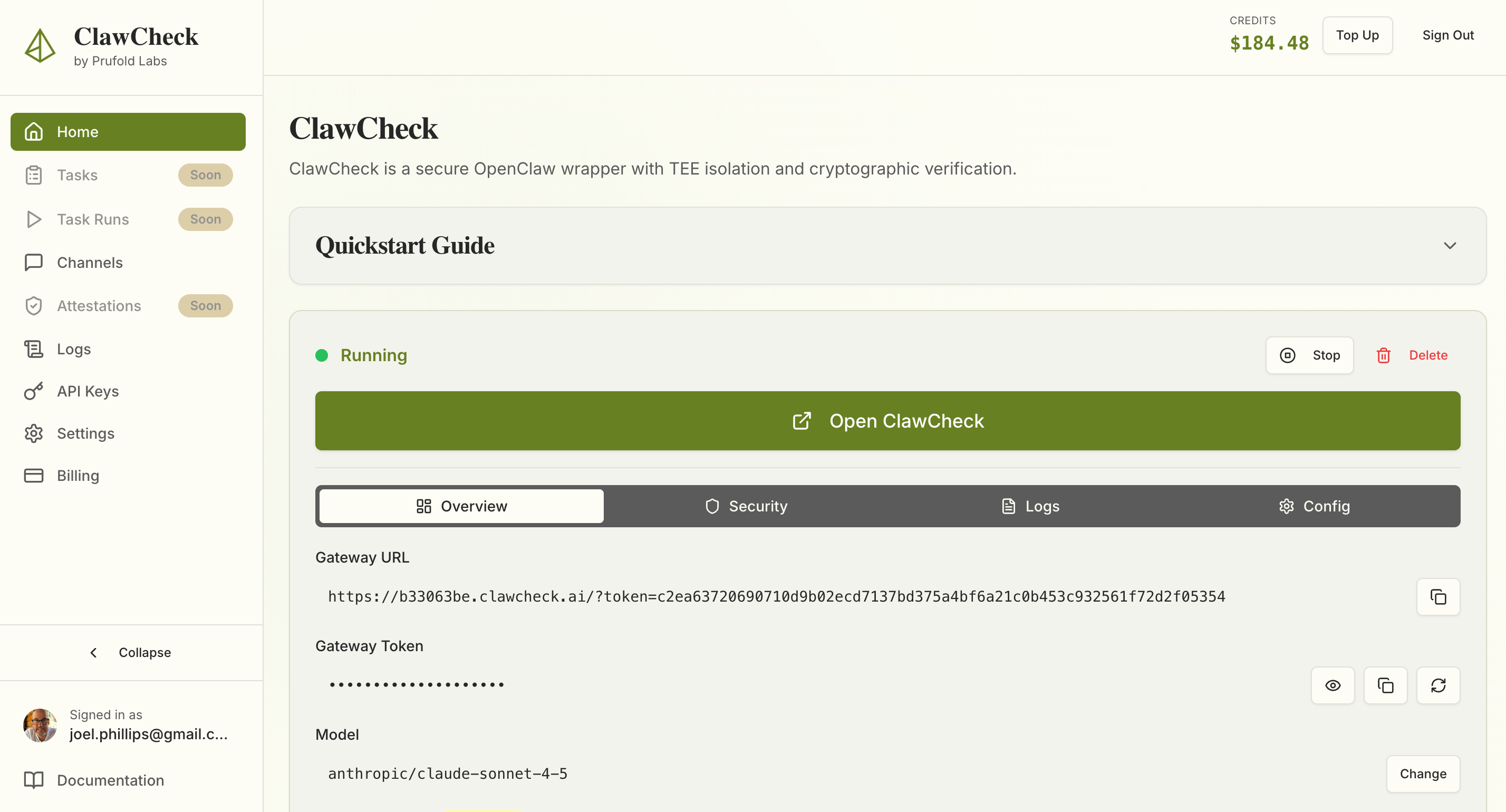
Getting started takes less than a minute. Sign in at app.prufoldlabs.ai and you'll have a fully isolated, cryptographically verified OpenClaw gateway running immediately.
We're offering early access to teams dealing with regulated data, multi-channel deployments, or compliance requirements that probabilistic scanning can't satisfy. If you're facing an August 2nd EU AI Act deadline or need to demonstrate provable security properties to your CISO, sign up for early access.
Reach out at hello@prufold.ai. We can show you the transparency logs, walk through the attestation chain, and explain exactly how the ZK proofs work without the hand-waving.
This isn't about selling you on cryptography. It's about showing you a different way to think about AI security, where you don't have to trust our claims because the math speaks for itself.